Configuraremos un DAG
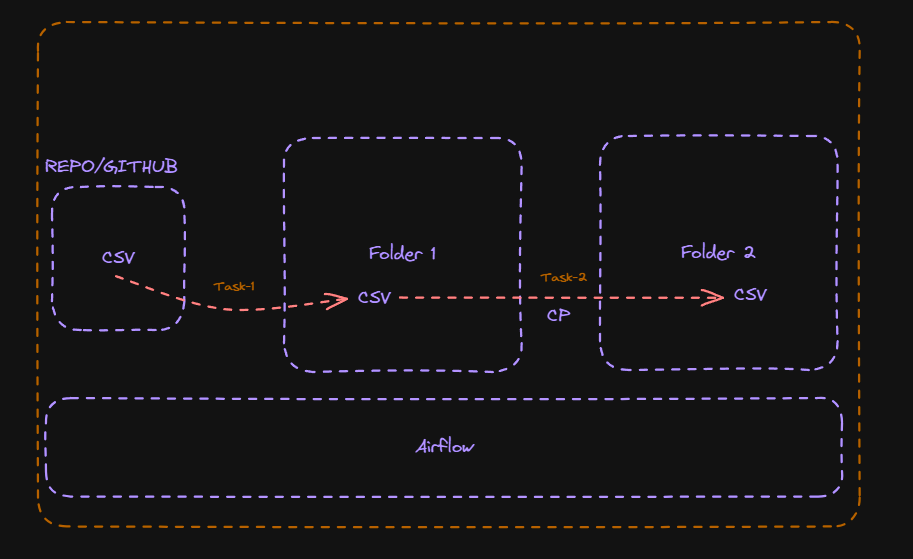
En esta sección, vamos a configurar un DAG para ejecutar nuestra primera tarea. El objetivo es sencillo: debemos mover datos de una ubicación a otra dentro del mismo host, utilizando Linux como sistema operativo.
Imaginemos que disponemos de una carpeta local en Linux donde diariamente se depositan archivos CSV. Normalmente, estos archivos se copian desde la carpeta de depósito a otra ubicación donde serán procesados utilizando Pandas para obtener ciertos resultados, los cuales posteriormente son almacenados como tablas en PostgreSQL. Todo este proceso se realiza manualmente en la actualidad, pero ahora queremos automatizar el proceso de mover estos archivos CSV de una carpeta a otra utilizando Airflow, con el fin de evitar errores inherentes a los procesos manuales.
Este proceso lo dividiremos en dos partes: proceso manual y proceso automatizado(Airflow), con el objetivo de comparar ambas soluciones
Mini-Data-Platform
Antes de proceder con los procesos y para lograr lo anterior, debemos tener presente la estructura de la Mini-Data-Platform para utilizarla en la creación de las carpetas del proyecto dentro de esta misma ruta. Pero antes, necesitamos conocer cuál es la estructura de la plataforma. Para hacerlo, vamos a conectarnos a Machine-0 y utilizar el comando Linux tree. Este comando muestra la estructura de directorios en forma de árbol, lo que facilita la visualización de la jerarquía de archivos y carpetas en un sistema de archivos determinado.
Una vez estemos conectados a Machine-0 y ubicados en /home/admin/, abrimos la terminal de VSCode y navegamos a /repos/ y clonaremos el siguiente repositorio:
git clone https://github.com/xploiterx/mini-data-platform
cd /repos/mini-data-platform-dev/
Después de esto ejecutamos en la terminal los dos siguientes comandos:
sudo apt update
sudo apt install tree
El comando sudo apt update actualiza la lista de paquetes disponibles para instalar en un sistema Ubuntu o basado en Debian. Esto garantiza que el sistema esté al tanto de las últimas versiones de los paquetes disponibles en los repositorios.
El comando sudo apt install tree instala la utilidad "tree" en el sistema. "tree" es una herramienta que muestra la estructura de directorios en forma de árbol en la línea de comandos, lo que facilita la visualización y navegación de los directorios y archivos en el sistema de archivos.
Una vez ejecutado estos dos comandos podemos correo el comando tree desde la terminal
Si queremos listar solo los directorios y no los archivos, podemos usar tree -d.
tree -d
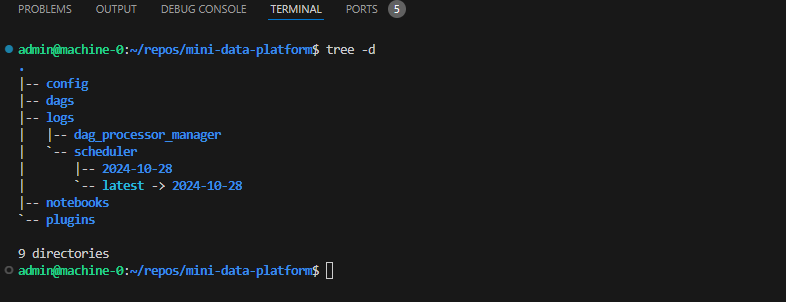
└── repos
└── mini-data-platform
├── config
├── dags
├── logs
│ ├── dag_processor_manager
│ └── scheduler
│ ├── 2024-05-08
│ └── latest -> 2024-05-08
├── notebooks
└── plugins
11 directories
Algunos contenidos que verás al ejecutar el comando tree pueden ser ligeramente diferentes de los que aparecen en la terminal de VS Code
Validemos la estructura de directorios en forma de árbol:
└──: Este símbolo indica que el directorio siguiente es el último hijo del directorio anterior en la estructura de árbol.repos: Es el directorio raíz en este ejemplo.mini-data-platform: Es un subdirectorio dentro derepos.config,dags,logs,notebooks,plugins: Estos son subdirectorios dentro demini-data-platform.config,dags,logs,notebooks,plugins: No se muestra ningún contenido dentro de estos directorios porque el comandotree -dsolo muestra la estructura de directorios, no los archivos.logs: Este directorio tiene subdirectorios adicionales dentro de él.dag_processor_manager,scheduler: Son subdirectorios dentro delogs.2024-05-08: Es un subdirectorio dentro descheduler.latest -> 2024-05-08: Este es un enlace simbólico que apunta al directorio2024-05-08.
11 directories: Esta es una cuenta final que indica cuántos directorios se muestran en total en esta salida.
Ahora ejecutemos el comando tree:
tree
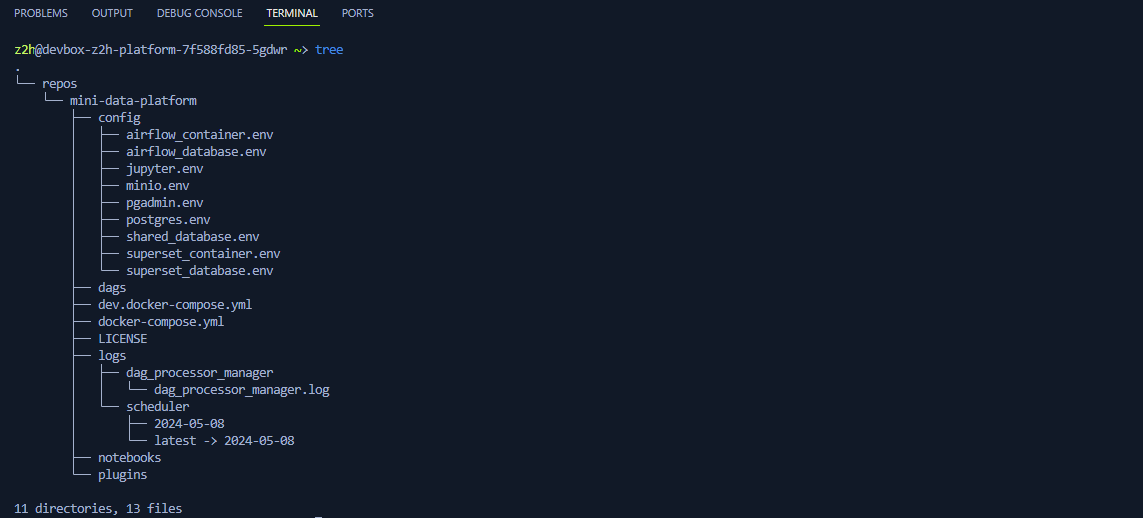
El comando tree nos permite listar todos los directorios, así como el contenido de archivos dentro de estos directorios. Más adelante explicaremos con más detalle el contenido de estos directorios, así como su función.
Creación del proyecto
Ahora que hemos revisado la estructura de los directorios que componen la Mini-Data-Platform, procederemos a crear una carpeta para el proyecto. En este caso, crearemos dos carpetas en la misma ubicación que el directorio actual y le asignaremos el nombre Proyectos a la primera carpeta y la segunda input donde almacenaremos los CSV.
mkdir Proyectos && mkdir Proyectos/input
El comando mkdir Proyectos && mkdir Proyectos/input se utiliza para crear dos directorios de manera secuencial.
mkdir Proyectos: Este comando crea un directorio llamadoProyectos.&&: Es un operador de control de flujo. En este contexto,&&significa "y". Indica que el siguiente comando solo se ejecutará si el comando anterior se ejecutó correctamente.mkdir Proyectos/input: Este comando crea un directorio llamadoinputdentro del directorioProyectos.
Ahora que hemos creado estas dos carpetas, procedamos a cargar los CSV dentro de la carpeta input. Estos CSV están alojados en GitHub, así que procederemos a descargarlos con el comando wget. Desde la terminal de VSCode, escribiremos los siguientes comandos, cada uno por separado:
cd Proyectos/input
sudo apt update
sudo apt install wget
Proceso Manual
Una vez ejecutados los comandos anteriores descarguemos el CSV en la carpeta input usando el comando wget que descargamos previamente:
wget https://raw.githubusercontent.com/xploiterx/datasets/master/Proyect-0/CSV/Churn_Modelling-1.csv
Ahora comprobemos que el CSV descargado con el comando ls ejecutándolo desde la terminal VSCode
ls
 Como podemos observar, el comando descargó exitosamente el archivo CSV
Como podemos observar, el comando descargó exitosamente el archivo CSV Churn_Modelling-1.csv, por lo que ahora procederemos a copiarlo desde la ruta actual a la carpeta /mini-data-platform/notebooks. Para hacer esto, usaremos el comando cp de Linux. La siguiente instrucción supone que actualmente estás ubicado en la ruta /repos/mini-data-platform/Proyectos/input.
cp ./Churn_Modelling-1.csv ~/repos/mini-data-platform/notebooks
El comando cp se utiliza para copiar archivos o directorios en Linux. Veamos paso a paso del comando lo hicimos:
cp: Este es el comando para copiar archivos o directorios../Churn_Modelling-1.csv: Esto indica el archivo que se copiará../representa el directorio actual, yChurn_Modelling-1.csves el nombre del archivo que se copiará desde el directorio actual.~/repos/mini-data-platform/notebooks: Esta es la ubicación de destino donde se copiará el archivo.~/representa el directorio de inicio del usuario actual o lo que es lo mismo/home/z2h/mini-data-platform/notebookssimplemente que con el~/nos ahorramos escribir/home/z2h/. Por lo tanto, esto copiará el archivoChurn_Modelling-1.csval directorionotebooksdentro demini-data-platform, que a su vez está dentro del directorioreposen el directorio de inicio del usuario.
Ahora, si validamos con el comando ls desde la ruta /mini-data-platform (recuerda retroceder dos directorio con cd .. cd ..) para posicionarte en /mini-data-platform y luego ejecuta el comando:
ls ~/repos/notebooks
Como podrás validar el Churn_Moedelling-1.csv fue copiado exitosamente.

Proceso Automático
Para automatizar este proceso, crearemos un DAG que se encargue de descargar este CSV de manera automática y luego moverlo a la ubicación deseada.
Paso 1: Configuración del DAG en Airflow
A partir de este sección trataremos de usar la terminal para la mayor parte del tiempo posible ya que parte de los objetivos inherente de los proyectos es desarrollar tus habilidades en Linux y docker
- Abre tu entorno de Airflow y navega hasta el directorio donde se almacenan los DAGs.
Si estás en la terminal de VScode y te encuentras en la ruta donde has descargado el archivo CSV Churn_Modelling-1.csv, estarás ubicado en la siguiente ruta.
/home/z2h/repos/mini-data-platform/Proyectos/input
Esta es la ruta absoluta en un sistema de archivos Linux. Revisemos en detalle:
/home/z2h/repos/mini-data-platform/Proyectos/input: Esto indica que el archivo o directorio está ubicado en la raíz del sistema de archivos, representado por/.home: Esto indica el directorio de inicio de un usuario. En este caso, el usuario tiene el nombrez2h.z2h: Es el nombre de usuario en este entorno Linux.repos: Este directorio contiene los repositorios de código relacionados con los proyectos en desarrollo.mini-data-platform: Este es el directorio que levanta los servicios de nuestra mini plataforma de datos.Proyectos: El directorio actual que contiene el subproyecto o recursos relacionados con el proyecto principal.input:Directorio dentro del proyectomini-data-platform, usado para almacenar archivos de entrada o datos que se utilizarán en el proyecto.
Ahora, ¿cómo nos movemos desde la terminal al directorio principal de mini-data-platform? En este caso, para regresar al directorio /home/z2h/repos/mini-data-platform/, simplemente usamos el comando cd ...
El comando cd .. se utiliza en Linux para cambiar el directorio actual al directorio padre del directorio actual. En otras palabras, "cd" es el comando para cambiar de directorio, y ".." es un directorio especial que representa el directorio padre del directorio actual. Por lo tanto, al ejecutar cd .., el sistema moverá el directorio actual un nivel hacia arriba en la jerarquía del sistema de archivos. Esto significa que estarás navegando al directorio que contiene el directorio actual. Es una forma rápida de retroceder al directorio superior cuando estás trabajando en la terminal.
En este caso debemos usar dos veces de la terminal el comando cd ..
z2h@devbox-z2h-platform-7f588fd85-5gdwr ~/r/m/P/input (main)> cd ..
z2h@devbox-z2h-platform-7f588fd85-5gdwr ~/r/m/Proyectos (main)> cd ..

Esto te posicionará en la ruta /home/admin/repos/mini-data-platform/, que es nuestro directorio principal. Ahora solo debemos navegar al directorio donde Airflow lee los DAGs que carguemos en este directorio. Para lograrlo, escribimos el siguiente comando:
cd mini-data-platform/dags
- Crea un nuevo archivo Python para el DAG. Por ejemplo,
download_csv_dag.py.
touch download_csv_dag.py
touch es un comando utilizado para crear un nuevo archivo vacío. Si el archivo ya existe, touch actualiza la fecha y hora de acceso y modificación del archivo al momento actual.
- Abre el archivo recién creado en un editor de texto o IDE.
Esta parte es opcional pero si quieres familiar aprender a usar herramientas de edición de texto como Nano en Linux es beneficioso porque proporciona una forma rápida y eficiente de crear, editar y visualizar archivos de texto directamente desde la terminal. Esto es especialmente útil en entornos de línea de comandos, donde no siempre es práctico o posible utilizar interfaces gráficas.
nano download_csv_dag.py
Nano es un editor de texto básico y fácil de usar en sistemas operativos tipo Unix, como Linux y macOS. Proporciona una interfaz de usuario simple en la terminal, lo que lo hace ideal para editar archivos de configuración, scripts y otros documentos de texto directamente desde la línea de comandos. Nano ofrece atajos de teclado intuitivos y funciones básicas de edición, como copiar, pegar, buscar y reemplazar, lo que lo convierte en una herramienta útil para usuarios principiantes y avanzados por igual.
En caso de que no desees utilizar
nano, puedes editar el archivodownload_csv_dag.pydesdeVSCode. El punto es copiar o bien sea en nano o desde el editor VSCode el siguiente código python para crear nuestroDAG
Paso 2: Definición del DAG
A continuación, definiremos el DAG que automatizará la descarga y el movimiento del archivo CSV.
Una recomendación muy importante a tener en cuenta es que no debes copiar y pegar el código en Python, ya que esto no es una buena práctica. Te sugerimos escribir todo el código manualmente para familiarizarte con cada segmento utilizado en el archivo Python.
Al escribir manualmente, es posible que cometas errores comunes, como errores tipográficos o que omitas algunas secciones del código, entre otros inconvenientes. Sin embargo, estos errores son parte del proceso de aprendizaje y te ayudarán a comprender mejor cómo funciona el código. La práctica constante y la revisión te permitirán mejorar tus habilidades en programación y minimizar estos errores en el futuro. Si te encuentras con errores al ejecutar el código en Python(DAG) en Airflow, puedes copiar y pegar el código de la docs para garantizar su correcta ejecución. Sin embargo, es recomendable que después de hacerlo, revises y entiendas cada parte del código. Esto te ayudará a aprender de los errores y mejorar tus habilidades como programador
Si al ejecutar Airflow te encuentras con errores, detén los contenedores como viste en la sección anterior. Luego, copia y pega el contenido en Python en el DAG y vuelve a ejecutar los contenedores para garantizar que todo esté correctamente configurado y que el DAG se ejecute de manera correcta en Airflow.
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 5, 13),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'download_csv_dag',
default_args=default_args,
description='DAG to download and move CSV file',
schedule_interval=None,
)
# Define tasks
download_csv_task = BashOperator(
task_id='download_csv',
bash_command='wget -O /opt/airflow/Proyectos/input/Churn_Modelling-1.csv https://raw.githubusercontent.com/xploiterx/datasets/master/Proyect-0/CSV/Churn_Modelling-1.csv',
dag=dag,
)
cp_csv_task = BashOperator(
task_id='cp_csv',
bash_command='cp /opt/airflow/Proyectos/input/Churn_Modelling-1.csv /opt/airflow/notebooks',
dag=dag,
)
# Define task dependencies
download_csv_task >> cp_csv_task
Este código define un DAG llamado download_csv_dag, que ejecuta dos tareas. La primera tarea, download_csv, descarga el archivo CSV utilizando el comando wget. La segunda tarea, move_csv, mueve el archivo descargado a la ubicación deseada utilizando el comando mv.
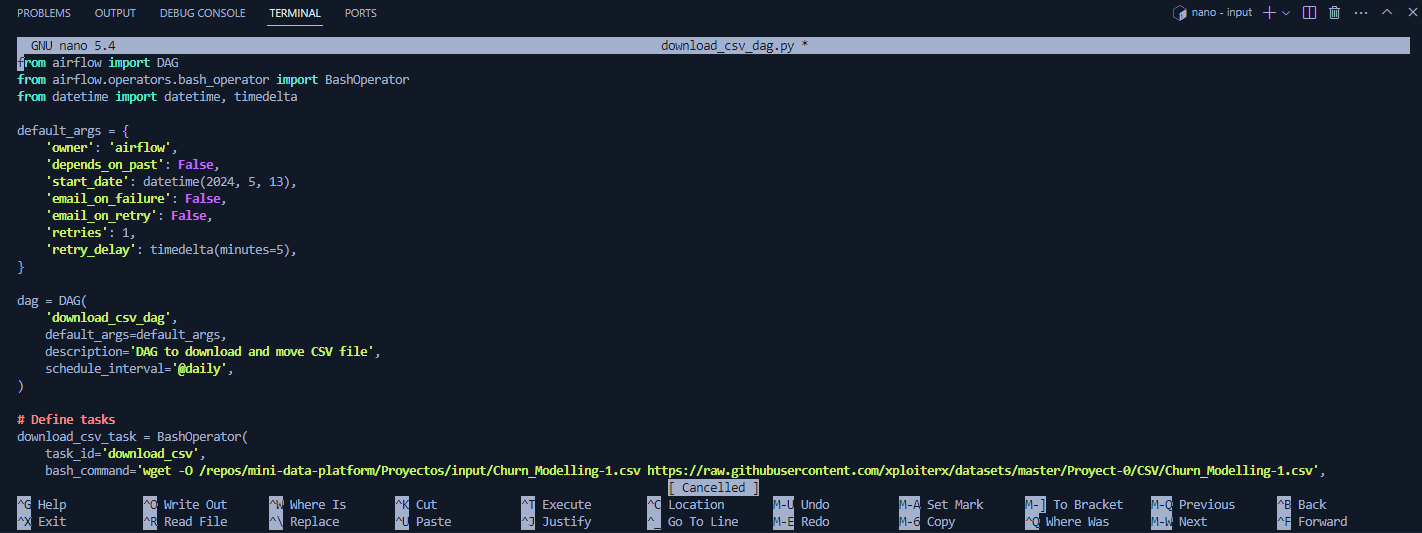
El anterior código lo puedes copiar en nano o en el editor de VSCode. Si lo haces con nano:
Copia el código anterior y lo pegas con Ctrl+v procedes a salvar los cambio con Ctrl+x y luego y para aceptar guardar los cambios y seguido de Enter para salir del editor nano
Paso 3: Ejecución del DAG
Antes de continuar con el siguiente paso, vamos a proceder a eliminar manualmente los dos archivos CSV llamados Churn_Modelling-1.csv que descargamos anteriormente. Estos archivos se encuentran ubicados en /notebooks/Churn_Modelling-1.csv y en Proyectos/input/Churn_Modelling-1.csv. Puedes eliminarlos desde el panel de navegación de VSCode haciendo clic derecho sobre el archivo CSV en ambas rutas.
Ahora, solo debemos levantar los servicios con docker compose -f airflow.docker-compose.yml up, como lo hemos visto en la sección anterior. Recuerda subir un nivel desde la ruta actual mini-data-platform/dags a mini-data-platform con el comando cd ..
cd ..
docker compose -f airflow.docker-compose.yml up
Cada vez que quieras ejecutar el comando docker compose -f airflow.docker-compose.yml up o docker compose -f airflow.docker-compose.yml down, siempre debes estar ubicado en la ruta /home/admin/repos/mini-data-platform. De lo contrario, los comandos no funcionarán. Pero esto lo explicaremos más adelante.
Recuerda detener los servicios de la mini-data-platform con Ctrl+c y docker compose -f airflow.docker-compose.yml down en caso de que estén en funcionamiento, ya que, como se explicó en la sección anterior, Airflow desplegado desde Docker no reconoce los nuevos archivos que agreguemos en la carpeta dag.
Si los recursos ya se iniciaron ahora solo debes dirigirte al localhost:7777 para acceder a la interfaz de Airflow
Debes esperar hasta que todos los contenedores de Docker estén ejecutándose correctamente. Si al navegar a localhost:7777 Airflow aún no carga en el navegador, es muy probable que el contenedor de Airflow no se esté ejecutando completamente. Por lo tanto, debes esperar hasta que Airflow se inicie por completo.
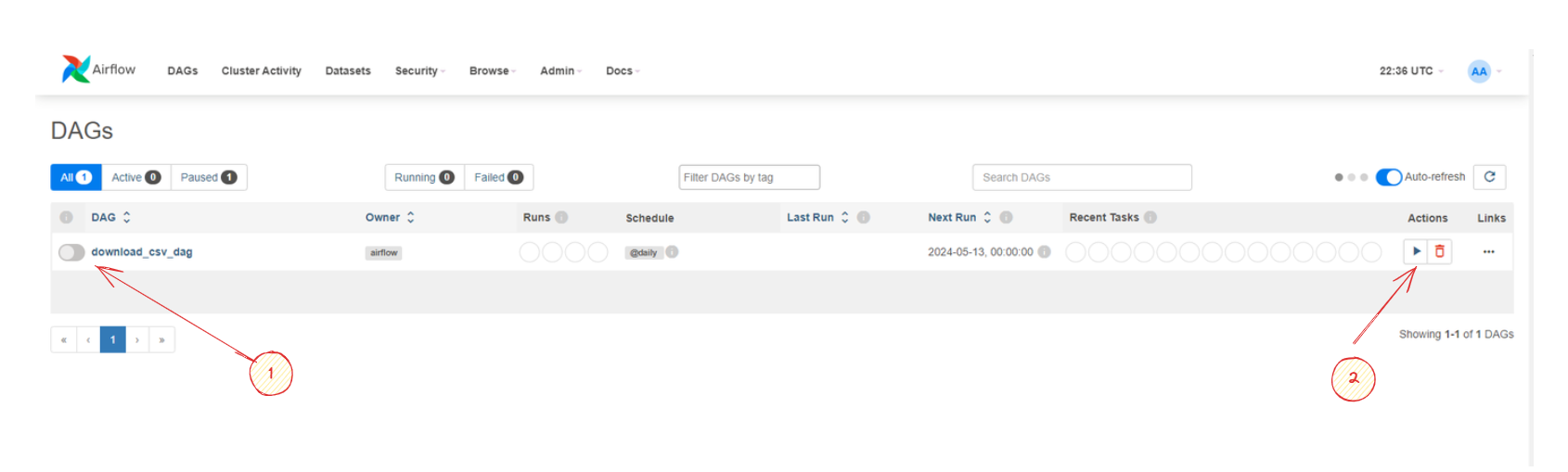
Como puedes observar en la imagen el DAG download_csv_dag.py ha cargado exitosamente en el portal Web. Como te habrás dado cuenta este DAG no se esta ejecutando ya que la fecha programada expiro por lo que debemos ejecutar el DAG manualmente haciendo clic en cualquier de las dos opciones en Airflow:
Pause/Unpause DAG- Cuando presionas este botón, detienes la ejecución del DAG si está activo, lo que significa que no se ejecutarán nuevas tareas dentro de ese flujo de trabajo hasta que se reanude. Esto puede ser útil si necesitas detener temporalmente la ejecución del DAG, por ejemplo, para realizar cambios o investigar problemas
- Al presionar nuevamente el botón, puedes reanudar la ejecución del DAG, permitiendo que las tareas dentro de él se ejecuten según lo previsto
Trigguer DAG:- Este botón inicia manualmente la ejecución del DAG, independientemente de cualquier programación predefinida o activación basada en disparadores. Puedes usar esto para forzar la ejecución del flujo de trabajo en un momento específico, por ejemplo, para ejecutar una tarea fuera del horario programado debido a una necesidad urgente o para realizar pruebas.
- Al hacer clic en este botón, Airflow comenzará a ejecutar las tareas del DAG según su definición y las dependencias entre ellas. Esto puede ser útil para desencadenar manualmente flujos de trabajo en situaciones específicas.
Independientemente de la opción que hallas elegido el DAG se ejecutará según la programación definida (schedule_interval) y automatizará el proceso de descarga y movimiento del archivo CSV.
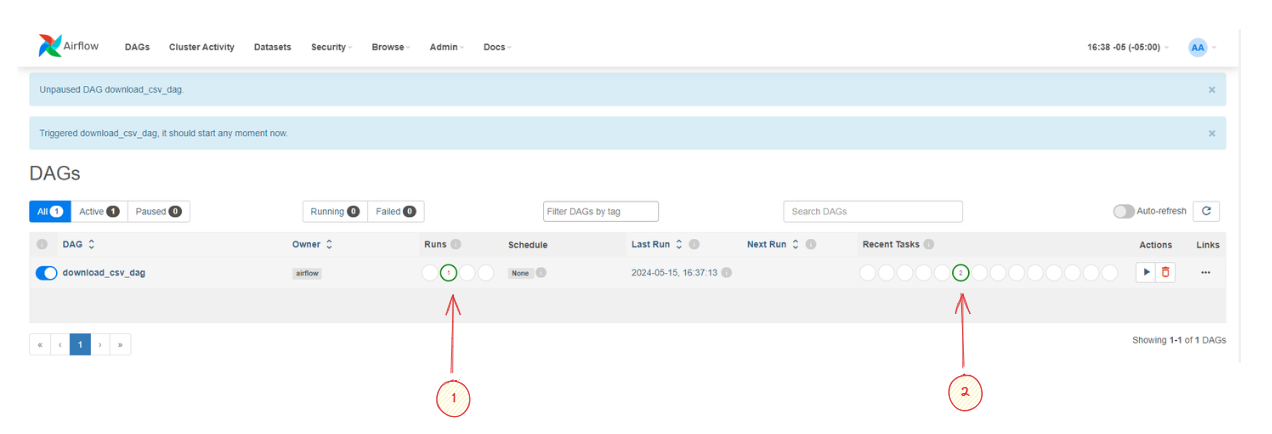
En Airflow, las herramientas "RUNS" (Ejecuciones) y "Recent Tasks" (Tareas Recientes) proporcionan información importante sobre el estado y el historial de ejecución de los DAG y las tareas dentro de ellos.
-
RUNS (Ejecuciones):
- Esta herramienta muestra una lista de todas las ejecuciones pasadas del DAG seleccionado.
- Cada fila en la lista representa una ejecución individual del DAG, con detalles como el estado de la ejecución, la fecha y hora de inicio y fin, la duración de la ejecución, etc.
- Al hacer clic en una ejecución específica, puedes ver detalles más detallados, como los registros de la ejecución, los errores encontrados, los tiempos de inicio y finalización de cada tarea, etc.
- Desde aquí, también puedes activar nuevas ejecuciones del DAG manualmente si el DAG no está programado para ejecutarse automáticamente en intervalos regulares.
-
Recent Tasks (Tareas Recientes):
- Esta herramienta muestra una lista de las tareas más recientes ejecutadas dentro del DAG seleccionado.
- Cada fila en la lista representa una tarea individual y proporciona detalles como el estado de la tarea, la fecha y hora de inicio y fin, la duración de la tarea, etc.
- Al hacer clic en una tarea específica, puedes ver detalles adicionales, como los registros de la tarea, los errores encontrados, los tiempos de inicio y finalización, etc.
- Esta herramienta es útil para obtener una visión rápida del estado y el progreso de las tareas más recientes dentro del DAG.
Al hacer clic en una ejecución o una tarea específica dentro de estas herramientas, se abre una página o un panel que muestra detalles más detallados sobre esa ejecución o tarea en particular, lo que te permite analizar y diagnosticar problemas, así como monitorear el progreso y el rendimiento del DAG y sus tareas.
En este caso Runs marca 1 lo que indica que tenemos una ejecución realizada y exitosa ya que el color verde representa success.

Por ejemplo al hacer clic en Runs sobre el botón verde:

Se abre el siguiente panel con información detallada del DAG.
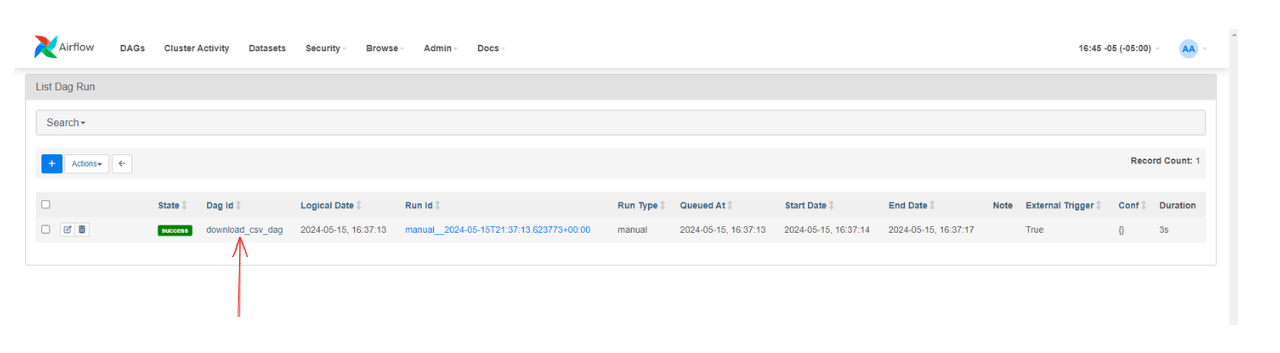
Y al hacer clic ahora en download_csv_dag se abre una página o un panel que muestra detalles más detallados sobre esa ejecución o tarea en particular:
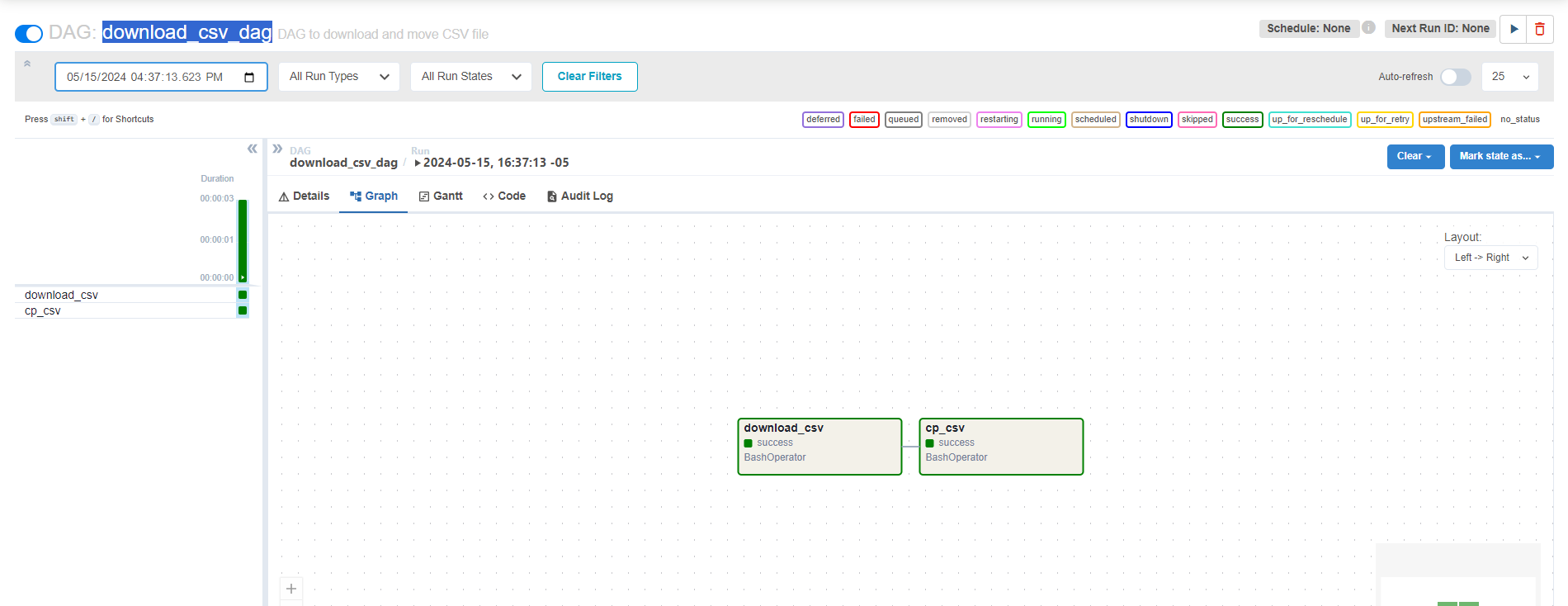
Con esto, has configurado con éxito un DAG en Airflow para automatizar el proceso de descarga y movimiento de archivos CSV. Este DAG eliminará la necesidad de realizar manualmente estas tareas y ayudará a evitar errores inherentes a los procesos manuales.
DAG Explicación detallada
-
Importaciones:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta- Se importa la clase
DAGde Airflow para definir el flujo de trabajo. - Se importa
BashOperatorde Airflow, que permite ejecutar comandos de shell en el sistema operativo como tareas en el DAG. - Se importa
datetimeytimedeltapara manejar fechas y tiempos en Python.
- Se importa la clase
-
Argumentos por defecto (
default_args):default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 5, 13),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
-
Se definen los argumentos por defecto para el DAG en un diccionario. Estos argumentos incluyen el propietario del DAG, si depende del pasado, la fecha de inicio, si se envía correo electrónico en caso de fallo o reintento, el número de reintentos y el retraso entre reintentos.
-
Así mismo este bloque de código define un diccionario llamado
default_args, que contiene los argumentos por defecto para el flujo de trabajo (DAG) en Apache Airflow. -
'owner': 'airflow': Esto indica quién es el propietario del flujo de trabajo. En este caso, se establece como'airflow'. -
'depends_on_past': False: Esto especifica si las tareas en el DAG deben depender del éxito de ejecuciones pasadas. En este caso, se establece comoFalse, lo que significa que las tareas no dependerán de sus ejecuciones pasadas para comenzar. -
'start_date': datetime(2024, 5, 13): Esto establece la fecha y hora de inicio del flujo de trabajo. En este caso, el flujo de trabajo comenzará el 13 de mayo de 2024. Es importante tener en cuenta que las tareas en el DAG no se ejecutarán antes de esta fecha. -
'email_on_failure': False: Esto determina si se enviará un correo electrónico en caso de que alguna tarea en el DAG falle. En este caso, se establece comoFalse, lo que significa que no se enviará ningún correo electrónico en caso de falla. -
'email_on_retry': False: Esto determina si se enviará un correo electrónico en caso de que una tarea en el DAG se reintente después de una falla. Al igual que'email_on_failure', se establece comoFalseaquí. -
'retries': 1: Esto especifica el número de reintentos que se deben realizar si una tarea en el DAG falla. En este caso, se establece como1, lo que significa que se realizará un reintentoo en caso de fallo. -
'retry_delay': timedelta(minutes=5): Esto establece el retraso entre los reintentos en caso de que una tarea falle. Aquí, se establece comotimedelta(minutes=5), lo que significa que habrá un retraso de 5 minutos antes de volver a intentar la tarea después de un fallo.
-
Creación del DAG:
dag = DAG(
'download_csv_dag',
default_args=default_args,
description='DAG to download and move CSV file',
schedule_interval='@daily',
)-
dag = DAG(: Aquí se está creando una nueva instancia de un DAG. El nombredages una convención común, pero puede ser cualquier identificador válido en Python. -
'download_csv_dag': Este es el nombre del DAG. En este caso, se llama "download_csv_dag". Es el identificador único del DAG en Airflow. -
default_args=default_args,: Aquí se está pasando un diccionario llamadodefault_argsque contiene argumentos predeterminados para las tareas del DAG, como la fecha de inicio, la dirección de correo electrónico del propietario, la política de reintentos, etc. Esto asegura que todas las tareas del DAG hereden estos argumentos predeterminados a menos que se especifiquen de otra manera. -
description='DAG to download and move CSV file',: Esta es una descripción opcional del DAG. Proporciona una breve explicación sobre lo que hace el DAG. -
schedule_interval=None,: Este es el intervalo de programación del DAG, es decir, con qué frecuencia se ejecutará. En este caso,Nonesignifica que no se programará de forma regular. El DAG se ejecutará manualmente o mediante algún otro disparador externo.
-
-
Definición de tareas:
download_csv_task = BashOperator(
task_id='download_csv',
bash_command='wget -O /opt/airflow/Proyectos/input/Churn_Modelling-1.csv https://raw.githubusercontent.com/xploiterx/datasets/master/Proyect-0/CSV/Churn_Modelling-1.csv',
dag=dag,
)
cp_csv_task = BashOperator(
task_id='cp_csv',
bash_command='cp /opt/airflow/Proyectos/input/Churn_Modelling-1.csv /opt/airflow/notebooks',
dag=dag,
)- Se definen dos tareas en el DAG:
download_csv_taskycp_csv_task. download_csv_taskutilizaBashOperatorpara ejecutar el comandowgety descargar un archivo CSV desde una URL específica.cp_csv_taskutilizaBashOperatorpara ejecutar el comandocpy copiar el archivo CSV descargado a otra ubicación en el sistema de archivos.
- Se definen dos tareas en el DAG:
-
Dependencias entre tareas:
download_csv_task >> cp_csv_task- Se establece la dependencia entre las tareas
download_csv_taskycp_csv_task. Esto significa quecp_csv_taskse ejecutará solo después de quedownload_csv_taskse complete con éxito. La sintaxis>>se utiliza para establecer esta relación de dependencia.
- Se establece la dependencia entre las tareas